

Una de las grandes ventajas de Data Studio es que nos permite crear campos personalizados con una flexibilidad relativamente amplia. Aunque se echan en falta algunas opciones y estamos bastante limitados en cuando al número de operadores contamos con algunas herramientas muy potentes para organizar nuestros datos de forma que nos permitan un análisis más claro de la información.
Uno de los operadores más prácticos en este sentido es el operador case. Con case vamos a poder evaluar una lista de condiciones y crear un campo calculado en el que organizar nuestros datos en función de nuestras necesidades. La función case permite dar un salto cualitativo en el uso de Data Studio. Personalmente la utilizo, por ejemplo, para diferenciar las distintas partes de una web y entender en qué secciones está llegando el tráfico. También la utilizo mucho con la Search Console para definir categorías de palabras clave y así entender la evolución del posicionamiento, no por una palabra clave, sino por un conjunto de palabras. Al agregar los datos vamos a poder tener una visión más clara de la evolución del posicionamiento.
En esta entrada vamos a ver varias formas en la que podemos utilizar la función case y construiremos un panel en el que veremos algunos casos prácticos en los que la función CASE nos permite una visualización más cómoda y útil de la información.
Uso de la función case
Utilizar la función CASE es muy sencillo. Sólo tenemos que definir un el conjunto de casos que queremos categorizar y para eso los vamos a colocar entre la palabra inicial CASE y la palabra final END. Entre las dos definiremos nuestras categorías utilizando WHEN para señalar una serie de casos que cumplan una condición y ELSE para los casos que no cumplan esta condición.
Por ejemplo, Google Analytics nos permite clasificar el tráfico que entra por su origen geográfico. En España vamos a poder jugar con dimensiones como «Región» que se corresponde con las Comunidades Autónomas y «Ciudad» que se corresponde con las ciudades. Con esto podemos crear, por ejemplo, una tabla dinámica que nos permita ver los datos agregados por estas dimensiones, algo así
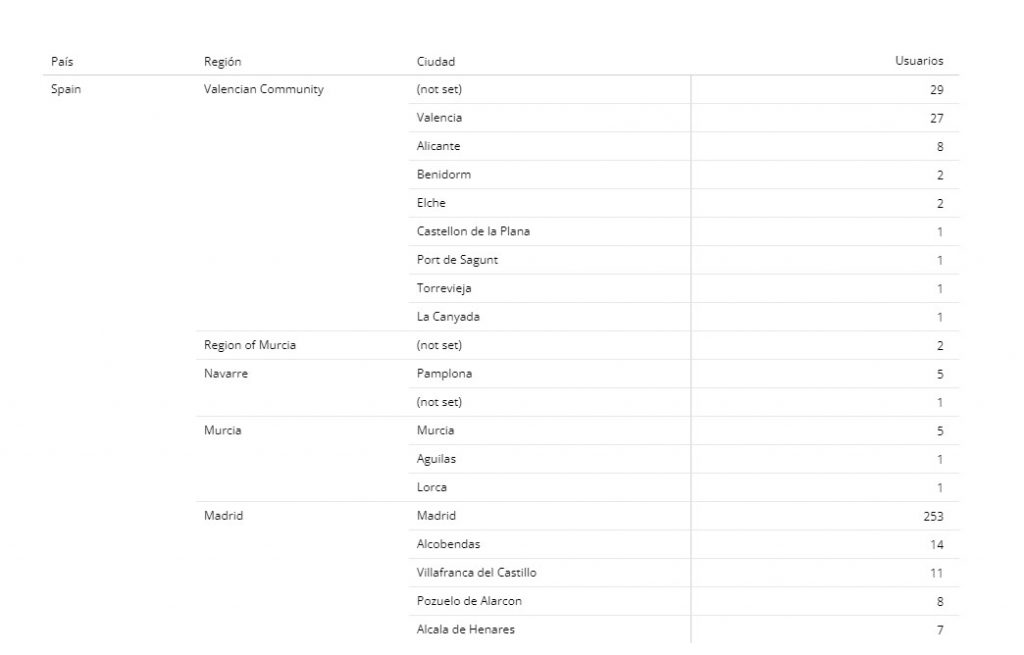
Perfecto. Ahora bien, en España muchos negocios tienen que diferenciar el tráfico de las distintas comunidades. Y por múltiples razones. Por ejemplo, algunos negocios dan servicio en algunas ciudades o algunas regiones, pero no en otras, así que puede ser interesante diferenciar rápidamente el tráfico entre las dos casuísticas. También es frecuente que el país esté dividido en areas comerciales y, muy a menudo, hay que diferenciar entre el tráfico que se produce dentro de la Península y el que proviene de las islas. Vamos a ver este ejemplo concreto. Como los datos están en inglés (para estos ejemplos estoy utilizando la cuenta de ejemplo de Google analytics) veo que google está llamando a Canarias «Canary islands» y a las Baleares «Balearic islands». Perfecto para nosotros. Sólo tenemos que pedirle a Google que distinga entre el tráfico que llega de las regiones que incluyen estos dos nombres y las que no. Podemos hacerlo así:
case
when Región in ("Balearic Islands","Canary Islands") then "Islas"
else "Península"
endLa fórmula no es complicada. Estamos creando un campo calculado pidiendo que, cuando la dimensión «Región» incluya «Balearic Islands» o «Canary Islans» incluya ese tráfico en la categoría «Islas». El resto del tráfico se incluye en la categoría «Península». Este es el caso más sencillo de uso de la función CASE. Simplemente, solicitamos que uno o varios casos se incluyan en una categoría concreta.
Crear un gráfico con CASE – WHEN para diferenciar tipos de tráfico
Si trabajas en SEO te encontrarás muy a menudo diferenciando el tráfico orgánico del resto del tráfico de la web. Hay muchas formas de hacerlo desde los propios informes de Analytics pero, con Data Studio y la función CASE vamos a poder crear muy fácilmente un gráfico que nos permita ver la evolución del tráfico de todos los canales y el canal orgánico por separarado. Vamos a utilizar este mismo sistema en una versión aún más sencilla
case
when Canal de adquisición in ("Direct") then "Directo"
else "Todos los demás"
end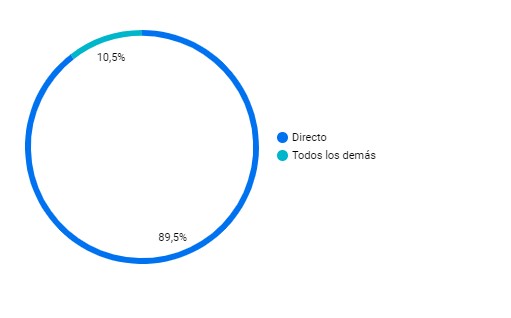
En realidad este sería el caso más sencillo posible para utilizar la función case y, de hecho, es tan sencillo que podríamos utilizar una función más simple. Nos bastaría con utilizar la función IF para crear la condición y, de esta forma, sólo tendríamos que escribir una línea de código, sería algo como
if(Canal de adquisición="Directo", "Directo", "Todo lo demás")
Utilizar la función CASE con expresiones regulares
Aquí es donde realmente empieza lo bueno. Con la función CASE no sólo vamos a poder clasificar uno por uno los casos de una determinada dimensión. Vamos a poder seleccionar conjuntos de dimensiones o de métricas utilizando una expresión regular y eso nos va a permitir clasificar grandes conjuntos de datos muy fácilmente. Un ejemplo es el que vimos arriba. Vamos a poder clasificar conjuntos de búsquedas en función de que se cumpla una regla determinada. Por ejemplo, vamos a poder distinguir en search console todos los datos que provienen de búsquedas de marca de los que no.
Utilicemos un ejemplo práctico. Digamos que tenemos acceso a los datos de la Search Console de, por ejemplo, Amazon y queremos saber cuándo del tráfico que nos llega corresponde a búsquedas de marca y cuáles no. Nos bastaría con una fórmula como esta
case
when regexp_match(query,".*mazon.*") then "Branded"
else "Unbranded"
endAquí he ido un poco a lo cómodo, pero sobre todo para centrarnos en entender la idea. Lo que estamos pidiendo aquí es que cuando la «Query» (que es el nombre de la dimensión en la Search console) cumpla con la condición .*mazon.* entonces lo clasifique como «Branded» y en todos los demás casos que lo considere «Unbranded». Aquí no vamos a ponernos a explicar cómo se utilizan las expresiones regulares en Data Studio. Básicamente lo que le hemos pedido es que independientemente de lo que haya delante o detrás (para esto los .*) si se encuentra con la palabra «mazon» (me salto la A para que nos coja las mayúsculas y las minúsculas) me lo clasifique como Marca.
Un ejemplo sobre cómo agrupar los idiomas utilizando la función CASE WHEN y expresiones regulares
Otro ejemplo para el que es muy útil la función CASE es a la hora de analizar el tráfico de una página por idiomas. Google analytics nos el desglose de los idiomas, pero los datos aparecen más o menos así
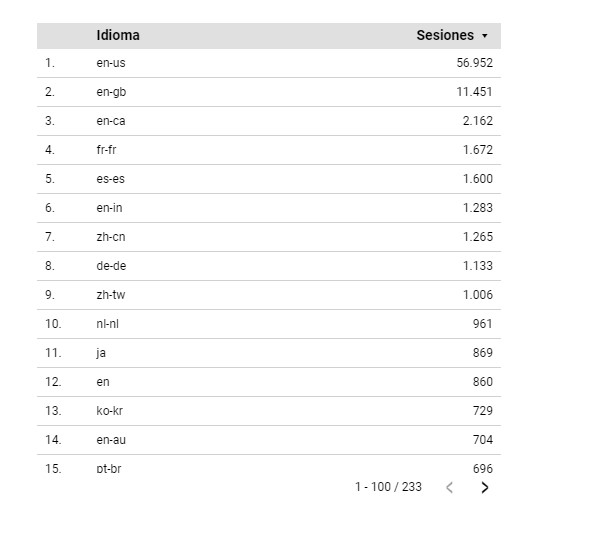
El problema es que en algunos casos tenemos los idiomas incluyendo el país (en-us) y en otros no (en) así que no tenemos una forma de ver directamente cuál es el idioma de navegación de los usuarios. Así que, aunque muchas veces sea interesante tener los datos de idioma y país habrá ocasiones en las que queramos ver únicamente el idioma utilizado por los usuarios. Este es un caso en el que la función case nos da solución muy sencilla, nos basta con decir que, cada vez que se encuentre las dos primeras letras del idioma, lo clasifique en su idioma correspondiente
case
when regexp_match(Idioma,"en.*") then "Inglés"
when regexp_match(Idioma,"fr.*") then "Francés"
when regexp_match(Idioma,"es.*") then "Español"
else "Others"
EndEn realidad aquí habría que incluir los códigos de todos los idiomas, aunque normalmente nos bastará con clasificar los cinco o seis más habituales y marcar el resto como «Otros». De todas formas, si lo que quieres crear es una dimensión nueva en la que se agrupen todos los idiomas por países en su momento me hice una chuleta con la expresión regular para clasificar todos los idiomas. Basta con copiar y pegar el código que dejo abajo.
case
when regexp_match(Idioma,"ab.*") then "abjasio (o abjasiano)"
when regexp_match(Idioma,"ae.*") then "avéstico"
when regexp_match(Idioma,"af.*") then "afrikáans"
when regexp_match(Idioma,"ak.*") then "akano"
when regexp_match(Idioma,"am.*") then "amhárico"
when regexp_match(Idioma,"an.*") then "aragonés"
when regexp_match(Idioma,"ar.*") then "árabe"
when regexp_match(Idioma,"as.*") then "asamés"
when regexp_match(Idioma,"av.*") then "avar (o ávaro)"
when regexp_match(Idioma,"ay.*") then "aimara"
when regexp_match(Idioma,"az.*") then "azerí"
when regexp_match(Idioma,"ba.*") then "baskir"
when regexp_match(Idioma,"be.*") then "bielorruso"
when regexp_match(Idioma,"bg.*") then "búlgaro"
when regexp_match(Idioma,"bh.*") then "bhoyapurí"
when regexp_match(Idioma,"bi.*") then "bislama"
when regexp_match(Idioma,"bm.*") then "bambara"
when regexp_match(Idioma,"bn.*") then "bengalí"
when regexp_match(Idioma,"bo.*") then "tibetano"
when regexp_match(Idioma,"br.*") then "bretón"
when regexp_match(Idioma,"bs.*") then "bosnio"
when regexp_match(Idioma,"ca.*") then "catalán"
when regexp_match(Idioma,"ce.*") then "checheno"
when regexp_match(Idioma,"ch.*") then "chamorro"
when regexp_match(Idioma,"co.*") then "corso"
when regexp_match(Idioma,"cr.*") then "cree"
when regexp_match(Idioma,"cs.*") then "checo"
when regexp_match(Idioma,"cu.*") then "eslavo eclesiástico antiguo"
when regexp_match(Idioma,"cv.*") then "chuvasio"
when regexp_match(Idioma,"cy.*") then "galés"
when regexp_match(Idioma,"da.*") then "danés"
when regexp_match(Idioma,"de.*") then "alemán"
when regexp_match(Idioma,"dv.*") then "maldivo (o dhivehi)"
when regexp_match(Idioma,"dz.*") then "dzongkha"
when regexp_match(Idioma,"ee.*") then "ewé"
when regexp_match(Idioma,"el.*") then "griego (moderno)"
when regexp_match(Idioma,"en.*") then "inglés"
when regexp_match(Idioma,"eo.*") then "esperanto"
when regexp_match(Idioma,"es.*") then "español (o castellano)"
when regexp_match(Idioma,"et.*") then "estonio"
when regexp_match(Idioma,"eu.*") then "euskera"
when regexp_match(Idioma,"fa.*") then "persa"
when regexp_match(Idioma,"ff.*") then "fula"
when regexp_match(Idioma,"fi.*") then "finés (o finlandés)"
when regexp_match(Idioma,"fj.*") then "fiyiano (o fiyi)"
when regexp_match(Idioma,"fo.*") then "feroés"
when regexp_match(Idioma,"fr.*") then "francés"
when regexp_match(Idioma,"fy.*") then "frisón (o frisio)"
when regexp_match(Idioma,"ga.*") then "irlandés (o gaélico)"
when regexp_match(Idioma,"gd.*") then "gaélico escocés"
when regexp_match(Idioma,"gl.*") then "gallego"
when regexp_match(Idioma,"gn.*") then "guaraní"
when regexp_match(Idioma,"gu.*") then "guyaratí (o gujaratí)"
when regexp_match(Idioma,"gv.*") then "manés (gaélico manés o de Isla de Man)"
when regexp_match(Idioma,"ha.*") then "hausa"
when regexp_match(Idioma,"he.*") then "hebreo"
when regexp_match(Idioma,"hi.*") then "hindi (o hindú)"
when regexp_match(Idioma,"ho.*") then "hiri motu"
when regexp_match(Idioma,"hr.*") then "croata"
when regexp_match(Idioma,"ht.*") then "haitiano"
when regexp_match(Idioma,"hu.*") then "húngaro"
when regexp_match(Idioma,"hy.*") then "armenio"
when regexp_match(Idioma,"hz.*") then "herero"
when regexp_match(Idioma,"ia.*") then "interlingua"
when regexp_match(Idioma,"id.*") then "indonesio"
when regexp_match(Idioma,"ie.*") then "occidental"
when regexp_match(Idioma,"ig.*") then "igbo"
when regexp_match(Idioma,"ii.*") then "yi de Sichuán"
when regexp_match(Idioma,"ik.*") then "iñupiaq"
when regexp_match(Idioma,"io.*") then "ido"
when regexp_match(Idioma,"is.*") then "islandés"
when regexp_match(Idioma,"it.*") then "italiano"
when regexp_match(Idioma,"iu.*") then "inuktitut (o inuit)"
when regexp_match(Idioma,"ja.*") then "japonés"
when regexp_match(Idioma,"jv.*") then "javanés"
when regexp_match(Idioma,"ka.*") then "georgiano"
when regexp_match(Idioma,"kg.*") then "kongo (o kikongo)"
when regexp_match(Idioma,"ki.*") then "kikuyu"
when regexp_match(Idioma,"kj.*") then "kuanyama"
when regexp_match(Idioma,"kk.*") then "kazajo (o kazajio)"
when regexp_match(Idioma,"kl.*") then "groenlandés (o kalaallisut)"
when regexp_match(Idioma,"km.*") then "camboyano (o jemer)"
when regexp_match(Idioma,"kn.*") then "canarés"
when regexp_match(Idioma,"ko.*") then "coreano"
when regexp_match(Idioma,"kr.*") then "kanuri"
when regexp_match(Idioma,"ks.*") then "cachemiro (o cachemir)"
when regexp_match(Idioma,"ku.*") then "kurdo"
when regexp_match(Idioma,"kv.*") then "komi"
when regexp_match(Idioma,"kw.*") then "córnico"
when regexp_match(Idioma,"ky.*") then "kirguís"
when regexp_match(Idioma,"la.*") then "latín"
when regexp_match(Idioma,"lb.*") then "luxemburgués"
when regexp_match(Idioma,"lg.*") then "luganda"
when regexp_match(Idioma,"li.*") then "limburgués"
when regexp_match(Idioma,"ln.*") then "lingala"
when regexp_match(Idioma,"lo.*") then "lao"
when regexp_match(Idioma,"lt.*") then "lituano"
when regexp_match(Idioma,"lu.*") then "luba-katanga (o chiluba)"
when regexp_match(Idioma,"lv.*") then "letón"
when regexp_match(Idioma,"mg.*") then "malgache (o malagasy)"
when regexp_match(Idioma,"mh.*") then "marshalés"
when regexp_match(Idioma,"mi.*") then "maorí"
when regexp_match(Idioma,"mk.*") then "macedonio"
when regexp_match(Idioma,"ml.*") then "malayalam"
when regexp_match(Idioma,"mn.*") then "mongol"
when regexp_match(Idioma,"mr.*") then "maratí"
when regexp_match(Idioma,"ms.*") then "malayo"
when regexp_match(Idioma,"mt.*") then "maltés"
when regexp_match(Idioma,"my.*") then "birmano"
when regexp_match(Idioma,"na.*") then "nauruano"
when regexp_match(Idioma,"nb.*") then "noruego bokmål"
when regexp_match(Idioma,"nd.*") then "ndebele del norte"
when regexp_match(Idioma,"ne.*") then "nepalí"
when regexp_match(Idioma,"ng.*") then "ndonga"
when regexp_match(Idioma,"nl.*") then "neerlandés (u holandés)"
when regexp_match(Idioma,"nn.*") then "nynorsk"
when regexp_match(Idioma,"no.*") then "noruego"
when regexp_match(Idioma,"nr.*") then "ndebele del sur"
when regexp_match(Idioma,"nv.*") then "navajo"
when regexp_match(Idioma,"ny.*") then "chichewa"
when regexp_match(Idioma,"oc.*") then "occitano"
when regexp_match(Idioma,"oj.*") then "ojibwa"
when regexp_match(Idioma,"om.*") then "oromo"
when regexp_match(Idioma,"or.*") then "oriya"
when regexp_match(Idioma,"os.*") then "osético (u osetio, u oseta)"
when regexp_match(Idioma,"pa.*") then "panyabí (o penyabi)"
when regexp_match(Idioma,"pi.*") then "pali"
when regexp_match(Idioma,"pl.*") then "polaco"
when regexp_match(Idioma,"ps.*") then "pastú (o pastún, o pashto)"
when regexp_match(Idioma,"pt.*") then "portugués"
when regexp_match(Idioma,"qu.*") then "quechua"
when regexp_match(Idioma,"rm.*") then "romanche"
when regexp_match(Idioma,"rn.*") then "kirundi"
when regexp_match(Idioma,"ro.*") then "rumano"
when regexp_match(Idioma,"ru.*") then "ruso"
when regexp_match(Idioma,"rw.*") then "ruandés (o kiñaruanda)"
when regexp_match(Idioma,"sa.*") then "sánscrito"
when regexp_match(Idioma,"sc.*") then "sardo"
when regexp_match(Idioma,"sd.*") then "sindhi"
when regexp_match(Idioma,"se.*") then "sami septentrional"
when regexp_match(Idioma,"sg.*") then "sango"
when regexp_match(Idioma,"si.*") then "cingalés"
when regexp_match(Idioma,"sk.*") then "eslovaco"
when regexp_match(Idioma,"sl.*") then "esloveno"
when regexp_match(Idioma,"sm.*") then "samoano"
when regexp_match(Idioma,"sn.*") then "shona"
when regexp_match(Idioma,"so.*") then "somalí"
when regexp_match(Idioma,"sq.*") then "albanés"
when regexp_match(Idioma,"sr.*") then "serbio"
when regexp_match(Idioma,"ss.*") then "suazi (o swati, o siSwati)"
when regexp_match(Idioma,"st.*") then "sesotho"
when regexp_match(Idioma,"su.*") then "sundanés (o sondanés)"
when regexp_match(Idioma,"sv.*") then "sueco"
when regexp_match(Idioma,"sw.*") then "suajili"
when regexp_match(Idioma,"ta.*") then "tamil"
when regexp_match(Idioma,"te.*") then "télugu"
when regexp_match(Idioma,"tg.*") then "tayiko"
when regexp_match(Idioma,"th.*") then "tailandés"
when regexp_match(Idioma,"ti.*") then "tigriña"
when regexp_match(Idioma,"tk.*") then "turcomano"
when regexp_match(Idioma,"tl.*") then "tagalo"
when regexp_match(Idioma,"tn.*") then "setsuana"
when regexp_match(Idioma,"to.*") then "tongano"
when regexp_match(Idioma,"tr.*") then "turco"
when regexp_match(Idioma,"ts.*") then "tsonga"
when regexp_match(Idioma,"tt.*") then "tártaro"
when regexp_match(Idioma,"tw.*") then "twi"
when regexp_match(Idioma,"ty.*") then "tahitiano"
when regexp_match(Idioma,"ug.*") then "uigur"
when regexp_match(Idioma,"uk.*") then "ucraniano"
when regexp_match(Idioma,"ur.*") then "urdu"
when regexp_match(Idioma,"uz.*") then "uzbeko"
when regexp_match(Idioma,"ve.*") then "venda"
when regexp_match(Idioma,"vi.*") then "vietnamita"
when regexp_match(Idioma,"vo.*") then "volapük"
when regexp_match(Idioma,"wa.*") then "valón"
when regexp_match(Idioma,"wo.*") then "wolof"
when regexp_match(Idioma,"xh.*") then "xhosa"
when regexp_match(Idioma,"yi.*") then "yídish (o yidis, o yiddish)"
when regexp_match(Idioma,"yo.*") then "yoruba"
when regexp_match(Idioma,"za.*") then "chuan (o chuang, o zhuang)"
when regexp_match(Idioma,"zh.*") then "chino"
when regexp_match(Idioma,"zu.*") then "zulú"
endDejo aquí el panel que he creado con estas funciones.




